Paper Reading: Distilling the Knowledge in a Neural Network
Abstract
This paper is written by the Deep Learning Pioneer, Geoffrey Hinton at 2015. I would like to concluded the main idea as follows. A strong Neural Network can teach a weak Neural Network that helps the weak model learns better. Please refer to the original publication: Distilling the Knowledge in a Neural Network for complete understanding.
Motivation: The Trade-off between Accuracy and Speed
Be accurate or be fast, there is always a trade-off. Considering a scenario, we have a weak model that inferences fast and a strong model that works slow.
Trade-off between two models
If the speed is the hard requirement, we can only pick the weak model for deployment.
The typical training of a predictive model
It seems like having a strong but slower model does not benefit us in this scenario. But the Model Distillation shows a way to improve the weak model by using the strong model as a teacher. Even in the case not having a strong model, we can always build one by almighty ensemble methods.
How Distillation Works?
To distill a model, we firstly train a strong network as a teacher for the next stage.
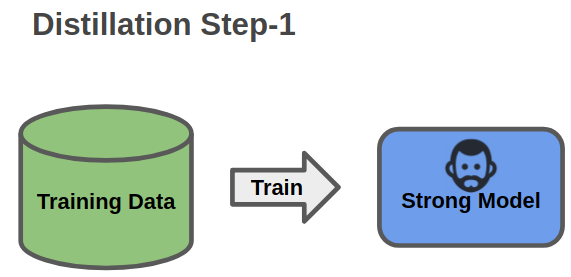
First step of Model Distillation
In second stage, we take the probabilities of predictions from the strong model as the second ground truth. The weak network then combines the original loss and the extra soft targets loss from the teacher network.
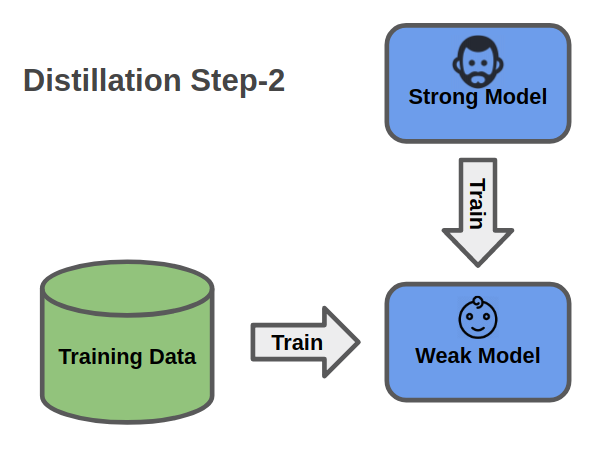
Second step of Model Distillation
#The loss of Model Distillation
loss = classification_loss + soft_target_loss
You may wonder how does the soft target loss contributes to the learning. Since the teacher network is also trained on the same training data, where does the extra information come from?
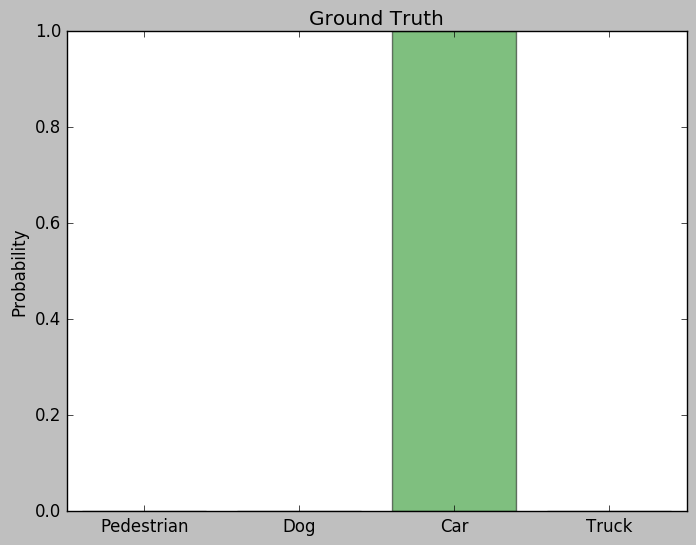
Imagine we are doing a image classification task with four classes: [Pedestrian, Dog, Car, Truck].
Given an image of a car and a trained teacher model, we got a prediction result from the teacher model like this:

A training data of Car
 |
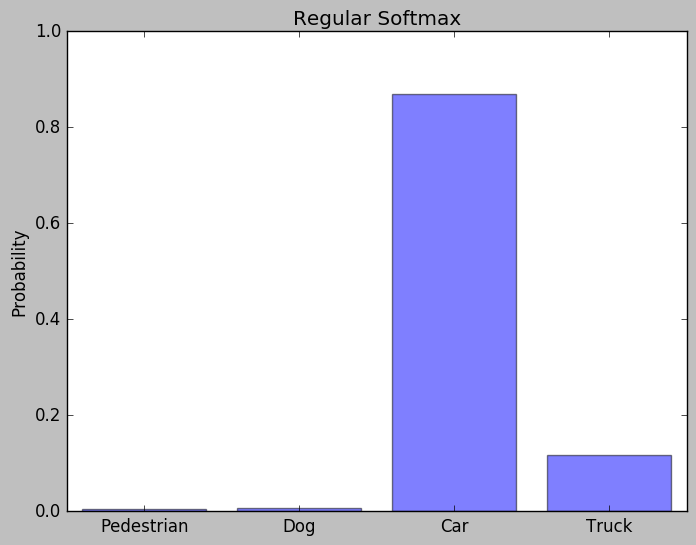 |
Ground Truth vs Prediction from the teacher network
As you can see, the model made the correct prediction on car. Compare to the ground truth, the only difference is the tiny probabilities on the rest of the incorrect classes.
Surprisingly, this small difference is the key of Model Distillation. Let’s find out in next section.
The Knowledge of Generalization
These extra probabilities provide the knowledge of generalization we need. The relatively higher likelihood of the truck shows that cars are more similar to trucks than to pedestrian or dogs. This extra information is the target we want to extract from Model Distillation.
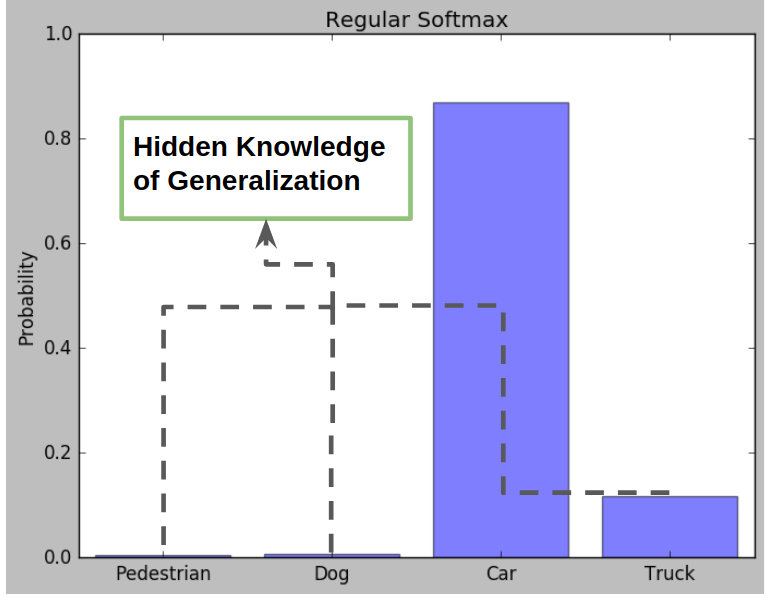 The knowledge of generalization from teacher network
The knowledge of generalization from teacher network
In order to extract these knowledges, Hinton introduces Softmax with temperature to replace the regular softmax. It works like softmax with a hyperparameter T.
The regular softmax functions:
Softmax with Temperature for Model Distilling:
Higher temperature mitigates the difference among classes thus enlarge the hidden knowledge of generalization. By mimicking the teacher network, the student network learns the extra knowledge of generalization that missing in ground truth.
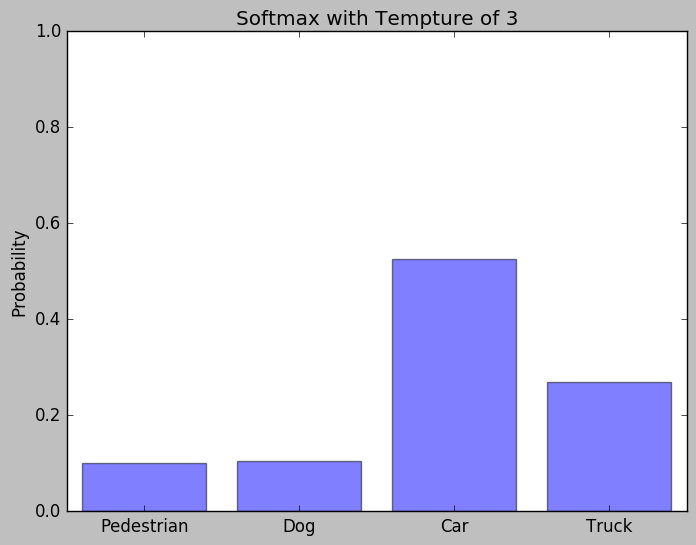 Probability distribution when T=3
Probability distribution when T=3
With higher T, we are able to extract the knowledge of generalization from the teacher network.
Extra Readings
Here is a great tensorflow implementation of Model Distillation by Dushyanta Dhyani.
Since the publication of Model Distillation, tons of related works have been done. Distillation had become an important concept escecially in the field of Neural Network Compression. Please refer to the Awesome Knowledge Distillation Collection for the awesome related works.