Distilling the Knowledge in a Neural Network: 讓神經網路模型教導另一個模型
概述
這篇論文是深度學習的先驅, Geoffrey Hinton在2015年寫的
中心概念我總結如下, 一個較強的Neural Network可以教導另一個較弱的Neural Network, 讓它學的更好
原文在此: Distilling the Knowledge in a Neural Network
動機: 準度與速度的兩難
選擇Model總是有準度與速度的取捨
假設我們手上有兩個預測模型, 一個快速不準確, 另一個漫而準確
兩個Model
當我們在速度上有剛性需求, 那只能選擇比較快的那個模型
典型的訓練模式
在這個情況下, 擁有一個比較慢速但準確的model似乎一點幫助都沒有, 然而Model Distillation, 也就是模型蒸餾, 可以將這個大而慢的模型變成一個教導其他網路的老師, 即便手頭上沒有一個更準確的模型, 我們永遠可以用ensemble的方法兜出一個
Model Distillation的運作方式
首先, 將這個大的網路訓練起來作為一個Teacher Model
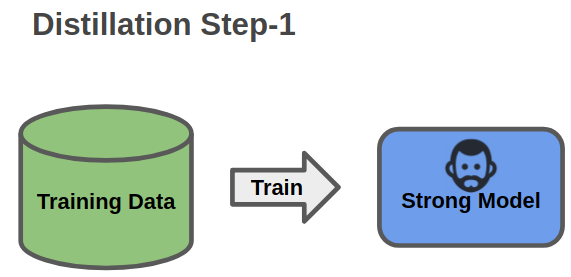
Model Distillation第一步
再來, 我們將Teacher Model的預測結果作為第二個Ground Truth
Weak Model則將原本的loss加上這個soft targets loss, 藉此模仿Teacher Network的行為
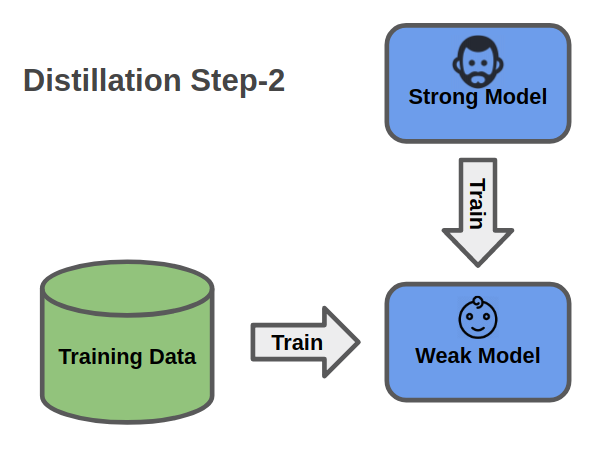
Model Distillation第二步
#The loss of Model Distillation
loss = classification_loss + soft_target_loss
讀到這裡, 你可能會有疑問, 既然Techer Network也是由相同的Training Data訓練出來的, 那麼為什麼可以幫助訓練呢?
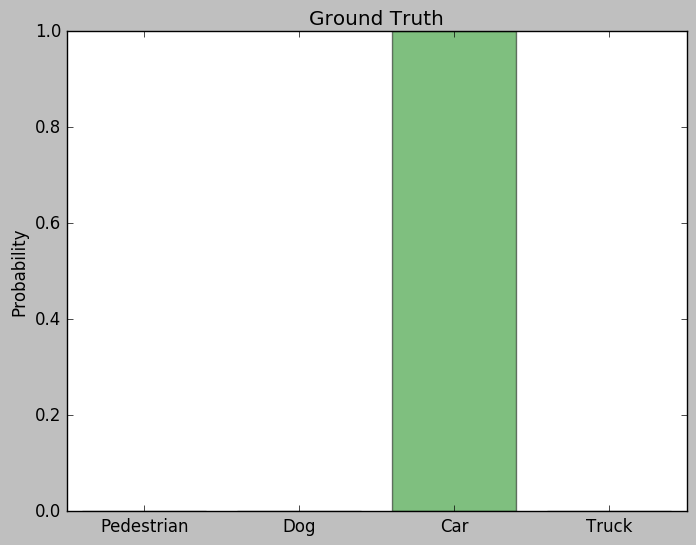
假設我們要做Image Classification的任務, 總共有四個類別要預測: [Pedestrian, Dog, Car, Truck]
給定一張車子的照片和訓練好的Teacher Model, 我們可以得到以下的預測機率

一張Car的訓練圖片
 |
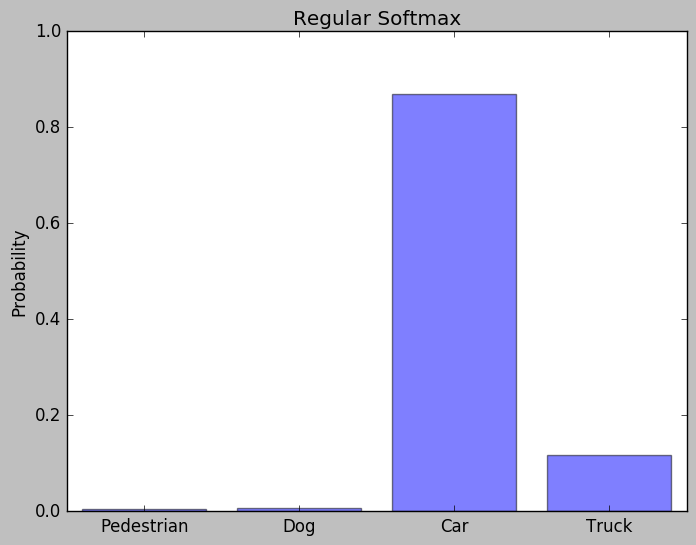 |
Ground Truth 與Techer Network的預測比較
如圖所示, 模型正確的推測出圖片中的車輛, 在Car的類別上有極高的機率, 唯一和Ground Truth的差別就是其他不正確類別仍然有微小的機率
而這微小的差距正是Model Distillation的關鍵, 下一步, 我們來理解背後的原理
泛化的知識
這些額外的機率提供了泛化的知識, 從truck相對較高的機率來看, 我們可以得知Car與Truck更為相近, 和Pedestrian或是Dog則不相似
這正是Model Distillation要萃取的目標
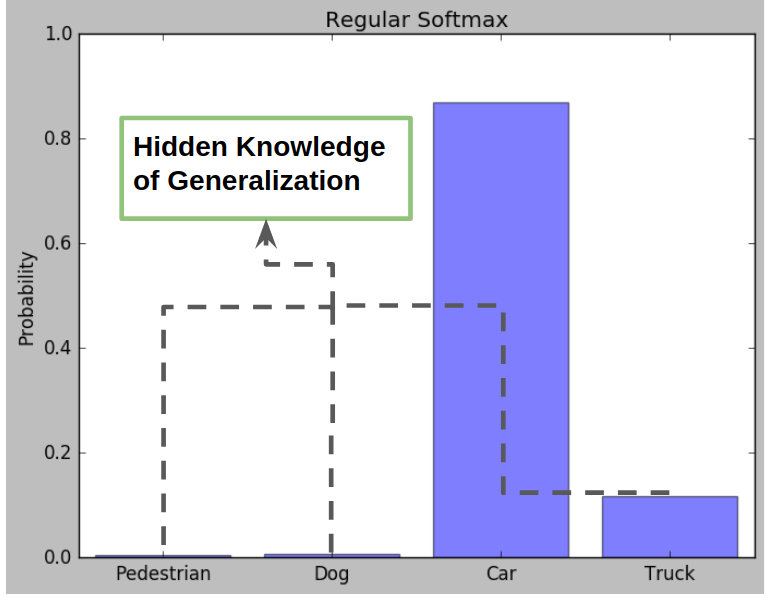 泛化的知識
泛化的知識
為了抽取這些泛化的知識, Hinton使用了Softmax with temperature來取代一般的softmax, 它的運作方式和典型的softmax類似, 只多了一個參數T
典型的Softmax:
Softmax with Temperature for Model Distilling:
當T提高的時候, classes之間的差異會被消弭, 增大我們要取得的泛化知識
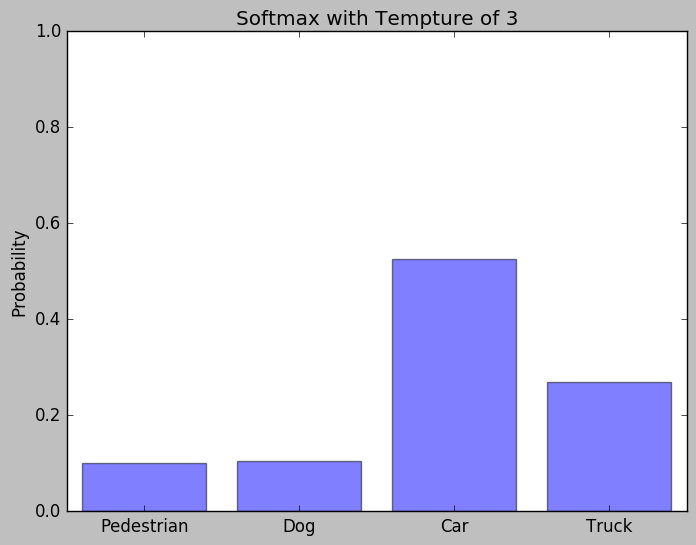
當T=3時的機率分佈
Model Distillation就是利用這較高的T從Teacher Network取得泛化知識
額外閱讀
Dushyanta Dhyani 的Tensorflow實踐, 寫的非常簡單好懂
另外這個2015年寫的論文被大量引用, 成為的Model Compression中的一大重要概念, 你可以在Awesome Knowledge Distillation Collection找到各種相關研究